|
Problťmatique
- Traitements classiques de l'informatique :
- Recherche d'une valeur dans un ensemble de valeurs
- Tri d'un ensemble de valeurs selon un critŤre d'ordre total
- Multiples algorithmes visant ŗ assurer ces traitements de la maniŤre la plus efficace possible
- Choix entre telle ou telle mťthode de traitement influencť par des critŤres tels que :
- Rapiditť intrinsŤque de l'algorithme (nombre d'instructions exťcutťes, nombre d'accŤs ŗ la mťmoire, ...)
- Taille de l'ensemble de donnťes
- Possibilitť particuliŤre d'exploitation des caractťristiques propres de l'ensemble de donnťes
- Taille de l'empreinte mťmoire (quantitť de mťmoire nťcessaire au fonctionnement) associťe ŗ tel ou tel algorithme
- Facilitť d'implantation de l'algorithme
- ...
Recherches
Recherches dans un "tas" de donnťes sans organisation particuliŤre
- Stockage des donnťes dans des tableaux -> donnťes de mÍme type
- ProblŤme : Rechercher une donnťe dans un tableau non particuliŤrement organisť :
- Test de prťsence
- Recherche de minimum
- Recherche de maximum
- Recherche de l'occurrence d'une chaÓne de caractŤres dans une autre chaÓne de caractŤres
- ...
- Algorithme naturel :
- Utilisation d'une variable "minimum courant" pour stocker le minimum dťjŗ trouvť
- Initialisation de cette variable avec la premiŤre valeur du tableau
- Parcours sťquentiel complet du reste du tableau au moyen d'un "pour"
- A chaque valeur parcourue, rťaffectation du minimum courant avec la valeur en cours si celle-ci est plus petite que le minimum courant
|
{ Recherche et retour de la valeur minimale }
{ prťsente dans un tableau d'entiers }
{ sans organisation particuliere }
{ Methode sequentielle }
{ t : le tableau d'entiers de recherche }
{ (au moins une valeur) }
entier fonction valeurMinimale(-> entier [] t)
entier i
entier min
min <- t[0]
si longueur(t) > 1 alors
pour i de 1 ŗ longueur(t)-1 faire
si t[i] < min alors
min <- t[i]
fsi
fait
fsi
retourner min
fin fonction
|
|
RechercheMinimum.lda |
|
/* Fonction de recherche et retour de la valeur */
/* minimale contenue dans un tableau de int */
/* sans organisation particuliere */
/* Methode sequentielle */
/* t : Le tableau d'entiers de recherche */
/* (au moins une valeur) */
static int valeurMinimale(int [] t) {
int min = t[0];
for ( int i = 1 ; i < t.length ; i++ ) {
if ( t[i] < min ) {
min = t[i]; } }
return min;
}
|
|
RechercheMinimum.java - Exemple d'exťcution |
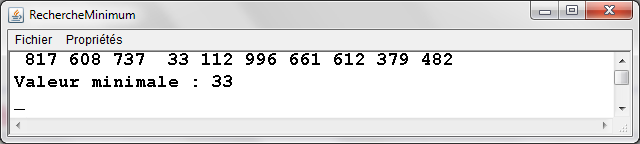 |
- Algorithme intuitif :
- Parcours sťquentiel possiblement complet du tableau au moyen d'un "tant que"
- A chaque valeur parcourue, si celle-ci est ťgale ŗ la valeur recherchťe, inutile d'aller plus loin car on l'a trouvťe
-> ArrÍter le parcours et retourner vrai
- DerniŤre valeur du tableau traitťe sans avoir trouvť la valeur recherchťe
-> Retourner faux
- Implantation
- Utilisation d'une variable boolťenne pour indiquer si la valeur recherchťe a ťtť trouvťe
- Initialisation de cette variable ŗ faux car, avant d'avoir vťritablement commencer ŗ chercher, on n'a pas trouvť
- Affectation de cette variable ŗ vrai au cours de la recherche si la valeur recherchťe est trouvťe
- Parcours sťquentiel au moyen d'un "tant que"
- parcours ťventuellement complet car on peut avoir ŗ rechercher jusqu'ŗ la derniŤre valeur
- parcours ťventuellement non complet car, si la valeur recherchťe a ťtť trouvťe, il n'est plus nťcessaire de continuer ŗ chercher
-> Construction d'une expression conditionnelle non canonique portant sur la variable boolťenne et sur l'indice de parcours
|
{ Test de la prťsence d'une valeur entiere }
{ dans un tableau d'entiers }
{ sans organisation particuliere }
{ Methode sequentielle }
{ Retour de vrai si prťsent, faux sinon }
{ v : Entier recherchť }
{ t : Le tableau d'entiers de recherche }
booleen fonction estPresent(-> entier v,
-> entier [] t)
booleen trouve <- faux
entier i <- 0
tantque ( trouve == faux ) et ( i < longueur(t) ) faire
si t[i] == v alors
trouve <- vrai
sinon
i <- i+1
fsi
fait
retourner trouve
fin fonction
|
|
RecherchePresence.lda |
|
/* Fonction de recherche de la presence */
/* d'une valeur entiere dans un tableau de int */
/* sans organisation particuliere */
/* Methode sequentielle */
/* Retour de true si prťsent, false sinon */
/* v : Entier recherchť */
/* t : Tableau d'entiers de recherche */
static boolean estPresent(int v,int [] t) {
boolean trouve = false;
int i = 0;
while ( ( trouve == false ) && ( i < t.length ) ) {
if ( t[i] == v ) {
trouve = true; }
else {
i++; } }
return trouve;
}
|
|
RecherchePresence.java - Exemple d'exťcution |
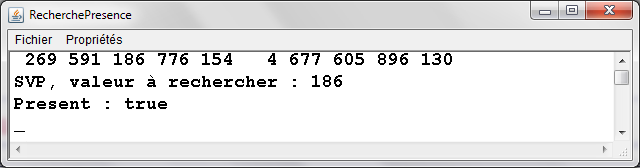 |
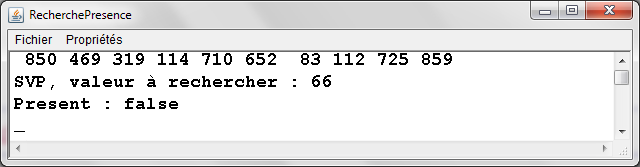 |
Recherches dans un ensemble de donnťes prťalablement triť
- ProblŤme : Rechercher une donnťe dans un ensemble de donnťes triť
- Optimisation des mťthodes de recherche sťquentielle utilisťes dans les algorithmes prťsentťs ci-dessus
- Implantation d'algorithmes fonctionnant de maniŤre diffťrente
- Recherche de la prťsence d'une valeur dans un tableau triť : Mťthode sťquentielle
- Interruption possible de la recherche dŤs que la valeur recherchťe respecte le critŤre de tri par rapport ŗ l'ťlťment courant du tableau
- Reconception de l'algorithme avec introduction d'une variable boolťenne "run" indiquant si la recherche doit Ítre continuťe ou
non et maintien de l'utilisation de la variable boolťenne "trouve" (celle sur laquelle porte le return) indiquant si la valeur a ťtť
trouvťe ou non
- Initialisation de run ŗ vrai, affectation ŗ faux pour arrÍter la recherche
- Initialisation de trouvť ŗ faux, affectation ŗ vrai si valeur recherchťe est trouvťe
- Parcours du tableau au moyen d'un "tant que" portant sur la variable run qui doit Ítre ťgale ŗ vrai pour que la recherche soit poursuivie.
A chaque ťtape de recherche :
- Si ťgalitť entre la valeur en cours et la valeur recherchťe, on a trouvť donc on stoppe la recherche en affectant faux ŗ run et vrai ŗ trouve.
- Si supťrioritť stricte de la valeur en cours par rapport ŗ la valeur recherchťe, on ne pourra pas trouver donc on stoppe la recherche en
affectant faux ŗ run et en laissant trouvť ŗ faux.
- Si infťrioritť stricte de la valeur en cours par rapport ŗ la valeur recherchťe, on poursuit la recherche ŗ la valeur suivante du tableau
s'il y en encore une. S'il n'y en a plus, on a parcouru intťgralement le tableau sans trouver la valeur recherchťe donc on stoppe la
recherche en affectant faux ŗ run et en laissant trouvť ŗ faux.
|
{ Test de la prťsence d'une valeur entiere }
{ dans un tableau d'entiers trie }
{ par ordre croissant }
{ Methode sequentielle }
{ Retour de vrai si prťsent, faux sinon }
{ v : Entier recherchť }
{ t : Le tableau d'entiers de recherche }
{ (triť par ordre croissant) }
booleen fonction estPresent(-> entier v,
-> entier [] t)
booleen trouve <- faux
booleen run <- vrai
entier i <- 0
tantque run == vrai faire
si t[i] == v alors
run <- faux
trouve <- vrai
sinon
si t[i] > v alors
run <- faux
sinon
i <- i+1
si i == longeur(t) alors
run <- faux
fsi
fsi
fsi
fait
retourner trouve
fin fonction
|
|
RecherchePresenceMethodeSequentielle.lda |
|
/* Recherche sequentielle de la presence */
/* d'un int dans un tableau de int triť */
/* par ordre croissant */
/* Retour de true si prťsent, false sinon */
/* v : Entier recherchť */
/* t : Tableau d'entiers de recherche */
/* (triť par ordre croissant) */
static boolean estPresent(int v,int [] t) {
boolean run = true;
boolean trouve = false;
int i = 0;
while ( run == true ) {
if ( t[i] == v ) {
run = false;
trouve = true; }
else {
if ( t[i] > v ) {
run = false; }
else {
i++;
if ( i == t.length ) {
run = false; } } } }
return trouve;
}
/* Recherche sequentielle de la presence */
/* d'un int dans un tableau de int trie */
/* Version optimisee */
/* v : Entier recherchť */
/* t : Tableau d'entiers de recherche */
/* (triť par ordre croissant) */
static boolean estPresent2(int v,int [] t) {
int i = 0;
while ( ( i != t.length ) && ( t[i] < v ) ) {
i++; }
return ( ( i < t.length ) && ( t[i] == v ) );
}
|
|
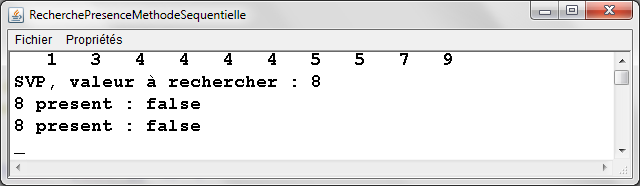
RecherchePresenceMethodeSequentielle.java -
Exemple d'exťcution |
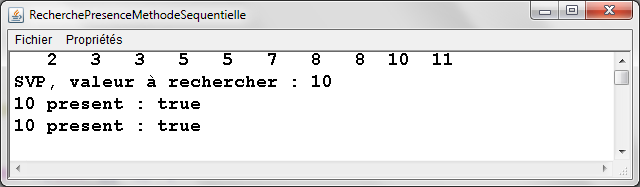 |
 |
- Recherche de la prťsence d'une valeur dans un tableau triť : Mťthode dichotomique
- Exploitation de l'ordre existant pour minimiser le nombre d'ťtapes de la recherche et donc accťlťrer son exťcution : Diviser pour
rťgner
- Algorithme par mťthode dichotomique
- Comparaison de la valeur mťdiane du tableau et de la valeur recherchťe.
Trois possibilitťs :
- Egalitť
- Infťrioritť stricte
- Supťrioritť stricte
- Si ťgalitť, prťsence de la valeur recherchťe dans le tableau
-> Inutile de continuer ŗ chercher
-> Retourner vrai
- Si valeur recherchťe plus petite que la valeur mťdiane, poursuite de la recherche dans le 1/2 tableau infťrieur selon le mÍme mode opťratoire
- Si valeur recherchťe plus grande que la valeur mťdiane, poursuite de la recherche dans le 1/2 tableau supťrieur selon le mÍme mode opťratoire
- Quand arrÍter la recherche ?
- Si tableau rťduit ŗ 1 ťlťment, retourner vrai si ťgalitť de cet ťlťment avec la valeur recherchťe, sinon retourner fauxux
- Si tableau rťduit ŗ 2 ťlťments, retourner vrai si ťgalitť de l'un de ses ťlťments avec la valeur recherchťe, sinon retourner faux
- Exemple : Soit le tableau de 15 valeurs entiŤres dans lequel la valeur 16 est recherchťe :
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Etape 1 :
- Indices des extrťmitťs de l'intervalle de recherche : 0 et 14
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Tableau non rťduit ŗ une ou deux valeurs
- Indice de la valeur mťdiane : (0+14)/2 = 7
-> Valeur mťdiane = 23
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- 23 plus grand que 16
-> Sťlection et poursuite sur le demi-tableau infťrieur d'indice 0 ŗ 7-1 = 6
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Etape 2 :
- Indices des extrťmitťs de l'intervalle de recherche : 0 et 6
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Tableau non rťduit ŗ une ou deux valeurs
- Indice de la valeur mťdiane : (0+6)/2 = 3
-> Valeur mťdiane = 15
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- 15 plus petit que 16
-> Sťlection et poursuite sur le demi-tableau supťrieur d'indice 3+1 = 4 ŗ 6
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Etape 3 :
- Indices des extrťmitťs de l'intervalle de recherche : 4 et 6
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Tableau non rťduit ŗ une ou deux valeurs
- Indice de la valeur mťdiane : (4+6)/2 = 5
-> Valeur mťdiane = 18
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- 18 est plus grand que 16
-> Sťlection et poursuite sur le demi-tableau infťrieur d'indice 4 ŗ 5-1 = 4
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Etape 4 :
- Indices des extrťmitťs de l'intervalle de recherche : 4 et 4
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Tableau rťduit ŗ une valeur
- Valeur ťgale ŗ la valeur recherchťe
-> ArrÍter et retourner vrai
|
10 |
12 |
12 |
15 |
16 |
18 |
21 |
23 |
23 |
25 |
28 |
29 |
31 |
33 |
36 |
- Seulement 4 ťtapes de recherche au lieu d'au maximum 15 par la mťthode sťquentielle
- Particularitť de l'implantation de l'algorithme :
- Utilisation de deux variables boolťennes run et trouve jouant les mÍmes rŰles que dans l'algorithme sťquentiel (voir paragraphe prťcťdent)
- Pas d'extraction vťritable des 1/2 tableaux
- Utilisation de deux variables entiŤres indiquant respectivement les indices initiaux et finaux (inclus) de la plage du tableau en cours pour la
recherche
- Dťtection du fait que la plage ne contient plus qu'un ťlťment : L'indice final est ťgal ŗ l'indice initial.
- Dťtection du fait que la plage ne contient plus que deux ťlťments : L'indice final est ťgal ŗ l'indice initial+1.
- Algorithme prťcis :
- Soit une suite de n valeurs triťe et stockťe dans un tableau aux indices ii=0 ŗ if=n-1
- Rťalisation du traitement itťratif suivant :
- Si ii ťgal if alors
- Si valeur ŗ l'indice ii ťgale valeur recherchťe alors arrÍter et retourner vrai sinon arrÍter et retourner faux
- Sinon si ii+1 ťgal if alors
- Si valeur ŗ l'indice ii ťgale valeur recherchťe ou si valeur ŗ l'indice if ťgale valeur recherchťe alors arrÍter
et retourner vrai sinon arrÍter et retourner faux
- Sinon trouver la valeur mťdiane vm ŗ l'indice im=(ii+if)/2
Si vm ťgale la valeur recherchťe alors arrÍter et retourner vrai
- Sinon si vm plus grande que la valeur recherchťe poursuivre la recherche dans la plage restreinte aux valeurs d'indice ii
ŗ if=im-1
- Sinon poursuivre la recherche dans la plage restreinte aux valeurs d'indice ii=im+1 ŗ if
|
{ Test de la prťsence d'une valeur entiere }
{ dans un tableau d'entiers trie }
{ par ordre croissant }
{ Methode dichotomique }
{ Retour de vrai si prťsent, faux sinon }
{ v : Entier recherchť }
{ t : Le tableau d'entiers de recherche }
{ (triť par ordre croissant) }
booleen fonction estPresent(-> entier v,
-> entier [] t)
booleen run <- vrai
booleen trouve <- faux
entier indi <- 0
entier indf <- longueur(t)-1
entier indm
tantque run == vrai faire
si indf == indi alors
si t[indi] == v alors
trouve <- vrai
fsi
run <- faux
sinon
si indf == indi+1 alors
si t[indi] == v ou t[indf] == v alors
trouve <- vrai
fsi
run <- faux
sinon
indm <- (indi+indf)/2
si t[indm] == v alors
run <- faux
trouve <- vrai
sinon
si v < t[indm] alors
indf <- indm-1
sinon
indi <- indm+1
fsi
fsi
fsi
fsi
fait
retourner trouve
fin fonction
|
|
RecherchePresenceMethodeDichotomique.lda |
|
/* Recherche dichotomique de la presence */
/* d'un int dans un tableau de int trie */
/* par ordre croissant */
/* Retour de true si prťsent, false sinon */
/* v : Entier recherchť */
/* t : Tableau d'entiers de recherche */
/* (triť par ordre croissant) */
static boolean estPresent(int v,int [] t) {
boolean run = true;
boolean trouve = false;
int indi = 0;
int indf = t.length-1;
int indm;
while ( run == true ) {
if ( indf == indi ) {
if ( t[indi] == v ) {
trouve = true; }
run = false; }
else {
if ( indf == indi+1 ) {
if ( ( t[indi] == v ) || ( t[indf] == v ) ) {
trouve = true; }
run = false; }
else {
indm = (indi+indf)/2;
if ( t[indm] == v ) {
run = false;
trouve = true; }
else {
if ( v < t[indm] ) {
indf = indm-1; }
else {
indi = indm+1; } } } } }
return trouve ;
}
|
|
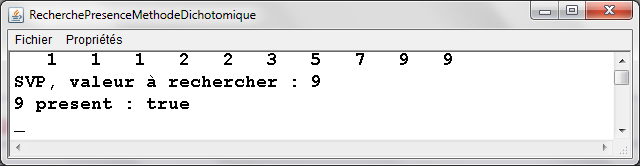
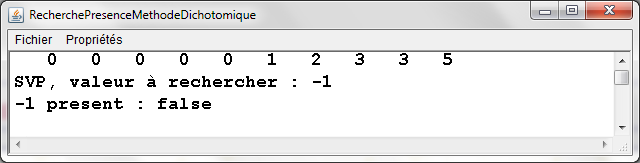
RecherchePresenceMethodeDichotomique.java -
Exemple d'exťcution |
 |
 |
- Inconvťnient de la recherche dichotomique : Complexitť algorithmique (pas extrŤme)
- Avantage de la recherche dichotomique : Grande rapiditť par rapport ŗ la recherche sťquentielle
- Algorithme sťquentiel : Nombre d'itťrations de l'ordre de la taille du tableau
- Algorithme dichotomique : Division par deux (approximativement) de la taille de l'espace de recherche ŗ chaque itťration
-> De l'ordre de log2(taille du tableau) itťrations de recherche
- MÍme si chaque itťration est individuellement un peu plus lourde car plus exigeante en traitements, au delŗ d'une certaine taille de tableau,
l'algorithme dichotomique devient plus efficace en terme de temps de calcul.
-> Augmentation rapide de l'avantage en terme de performance avec la taille des tableaux traitťs
|
Test des vitesses d'exťcution respectives en recherche sťquentielle et en recherche dichotomique
Taille
du tableau |
Temps moyen
en sťquentiel (ns) |
Temps moy. sťq.
/ taille |
Temps moyen
en dichotomique (ns) |
Temps moy. dichot.
/ log(taille) |
|
10 |
91,768 |
9,177 |
121,188 |
52,631 |
|
100 |
483,727 |
4,837 |
210,259 |
45,657 |
|
1000 |
4536,665 |
4,537 |
307,968 |
44,583 |
|
10000 |
44416,836 |
4,442 |
409,051 |
44,412 |
|
100000 |
442247,503 |
4,423 |
515,514 |
44,777 |
|
1000000 |
4438623,398 |
4,439 |
638,674 |
46,229 |
|
10000000 |
45025699,915 |
4,503 |
984,331 |
61,070 |
|
100000000 |
478664345,952 |
4,787 |
1401,123 |
76,063 |
|
Tris
- Stockage des donnťes ŗ trier dans un tableau or pour le trier il faut modifier ce tableau
-> Impossible de dťpasser la taille dťfinie pour ce tableau
-> Impossible de changer la taille de ce tableau une fois dťfinie
-> Impossible d'insťrer un ťlťment sans dťcaler au prťalable vers la droite tous les ťlťments au delŗ de la position d'insertion si ces
ťlťments doivent rester dans le mÍme ordre
-> Impossible de supprimer le trou gťnťrť par la suppression d'un ťlťment sans dťcaler vers la gauche tous les ťlťments au delŗ de la position
de suppression si ces ťlťments doivent rester dans le mÍme ordre
Contraintes lourdes et contraignantes avec un fort impact sur la facilitť d'implantation et sur les performances
Algorithme de tri naÔf
- Soit un "ensemble" de donnťes E
- ProblŤme : Trier cet ensemble selon un critŤre d'ordre total
- Algorithme naÔf :
- Crťer un deuxiŤme ensemble F vide
- Rťalisation de n (n = cardinal(E)) fois le traitement :
- Extraction de E de l'ťlťment e restant qui est le plus "petit" selon le critŤre de tri
- Dťplacement de e de l'ensemble E vers la premiŤre position disponible en tÍte de l'ensemble F
- Exemple : Tri par ordre dťcroissant d'un tableau de 10 entiers
|
|
E |
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
F |
|
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
|
- Etape 1 : Sťlection de l'entier 19
|
E |
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
- Etape 1 : Dťplacement de 19 vers le tableau triť
|
E |
|
16 |
15 |
12 |
10 |
12 |
15 |
--- |
18 |
10 |
16 |
|
|
19 |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
|
|
|
F |
- Etape 2 : Sťlection de l'entier 18
|
E |
|
16 |
15 |
12 |
10 |
12 |
15 |
--- |
18 |
10 |
16 |
|
|
- Etape 2 : Dťplacement de 18 vers le tableau triť
|
E |
|
16 |
15 |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
16 |
|
|
19 |
18 |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
|
|
|
F |
- Etape 3 : Sťlection de l'entier 16
|
E |
|
16 |
15 |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
16 |
|
|
- Etape 3 : Dťplacement de 16 vers le tableau triť
|
E |
|
--- |
15 |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
16 |
|
|
19 |
18 |
16 |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
|
|
|
F |
- Etape 4 : Sťlection de l'entier 16
|
E |
|
--- |
15 |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
16 |
|
|
- Etape 4 : Dťplacement de 16 vers le tableau triť
|
E |
|
--- |
15 |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
--- |
|
|
19 |
18 |
16 |
16 |
--- |
--- |
--- |
--- |
--- |
--- |
|
|
|
F |
- Etape 5 : Sťlection de l'entier 15
|
E |
|
--- |
15 |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
--- |
|
|
- Etape 5 : Dťplacement de 15 vers le tableau triť
|
E |
|
--- |
--- |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
--- |
|
|
19 |
18 |
16 |
16 |
15 |
--- |
--- |
--- |
--- |
--- |
|
|
|
F |
- Etape 6 : Sťlection de l'entier 15
|
E |
|
--- |
--- |
12 |
10 |
12 |
15 |
--- |
--- |
10 |
--- |
|
|
- Etape 6 : Dťplacement de 15 vers le tableau triť
|
E |
|
--- |
--- |
12 |
10 |
12 |
--- |
--- |
--- |
10 |
--- |
|
|
19 |
18 |
16 |
16 |
15 |
15 |
--- |
--- |
--- |
--- |
|
|
|
F |
- Etape 7 : Sťlection de l'entier 12
|
E |
|
--- |
--- |
12 |
10 |
12 |
--- |
--- |
--- |
10 |
--- |
|
|
- Etape 7 : Dťplacement de 12 vers le tableau triť
|
E |
|
--- |
--- |
--- |
10 |
12 |
--- |
--- |
--- |
10 |
--- |
|
|
19 |
18 |
16 |
16 |
15 |
15 |
12 |
--- |
--- |
--- |
|
|
|
F |
- Etape 8 : Sťlection de l'entier 12
|
E |
|
--- |
--- |
--- |
10 |
12 |
--- |
--- |
--- |
10 |
--- |
|
|
- Etape 8 : Dťplacement de 12 vers le tableau triť
|
E |
|
--- |
--- |
--- |
10 |
--- |
--- |
--- |
--- |
10 |
--- |
|
|
19 |
18 |
16 |
16 |
15 |
15 |
12 |
12 |
--- |
--- |
|
|
|
F |
- Etape 9 : Sťlection de l'entier 10
|
E |
|
--- |
--- |
--- |
10 |
--- |
--- |
--- |
--- |
10 |
--- |
|
|
- Etape 9 : Dťplacement de 10 vers le tableau triť
|
E |
|
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
10 |
--- |
|
|
19 |
18 |
16 |
16 |
15 |
15 |
12 |
12 |
10 |
--- |
|
|
|
F |
- Etape 10 : Sťlection de l'entier 10
|
E |
|
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
10 |
--- |
|
|
- Etape 10 : Dťplacement de 10 vers le tableau triť
|
E |
|
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
--- |
|
|
19 |
18 |
16 |
16 |
15 |
15 |
12 |
12 |
10 |
10 |
|
|
- Inconvťnient principal de cet algorithme : Pas d'optimisation de l'empreinte mťmoire
- Espace mťmoire nťcessaire au stockage de l'ensemble E + un espace mťmoire ťquivalent pour stocker l'ensemble F
- Autre inconvťnient : Crťation de trous dans l'ensemble E en cours de "vidage"
Exemple d'exťcution
Buts visťs par les algorithmes de tri classiques
- Implantation d'une empreinte mťmoire minimum : L'espace occupť par le tableau ŗ trier + les (quelques) variables de gestion de l'algorithme
-> Tri possible sans risque de dťpassement de capacitť mťmoire disponible
- Vitesse d'exťcution "optimale"
Performances
- A ne pas considťrer en valeur absolue mais en valeur relative
- ParamŤtres ayant une incidence directe sur la rapiditť d'exťcution :
- Langage de programmation
- Choix d'implantation
- Puissance de l'ordinateur
- Occupation de l'ordinateur
- ...
- Quatre types d'ensembles de donnťes testťs pour diffťrentes tailles
Sťrie alťatoire
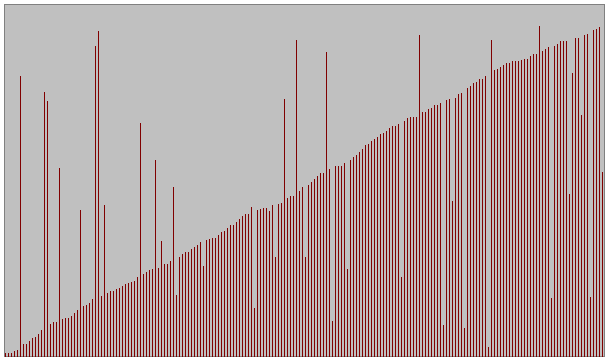
Sťrie quasiment triťe avec permutations entre les ťlements de n/10 couples de valeurs de positions alťatoires
(n : taille de l'ensemble)
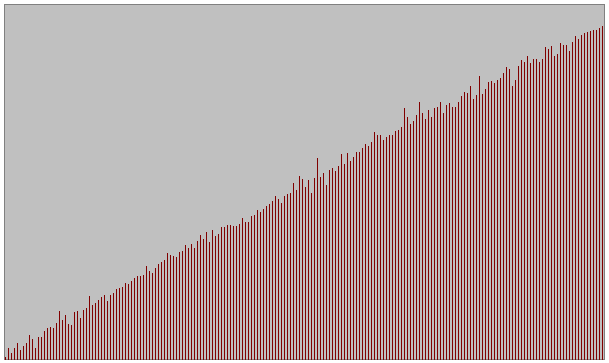
Sťrie quasiment triťe avec permutations entre les ťlements de n/10 couples de valeurs voisines
(n : taille de l'ensemble)
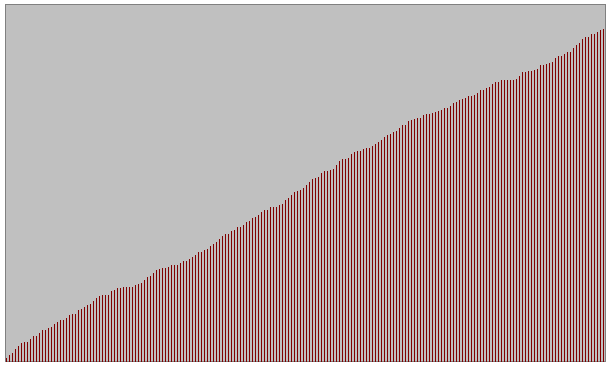
Sťrie dťjŗ triťe
Algorithme de tri par insertion
- Tri par insertion : Algorithme de tri naturellement utilisť par beaucoup de personnes (par exemple pour le tri de quelques cartes ŗ jouer)
- Soit un ensemble de donnťes E
- ProblŤme : Trier cet ensemble selon un critŤre d'ordre total (i.e. tout couple de donnťes est ordonnable selon le critŤre de tri)
- Algorithme :
- Rťalisation de n-1 (n = cardinal(E)) ťtapes de traitement numťrotťes i (ŗ partir de 1) :
- Extraction de E de l'ťlťment e d'indice i (indices comptťs de 0 ŗ n-1)
- Insertion de e ŗ sa place, selon la relation d'ordre du tri, dans la liste des ťlťments d'indice 0 ŗ i-1 (ťlťments dťjŗ triťs)
- Une place libťrťe par l'ťlťment d'indice i
-> Dťcalage possible de toutes les donnťes nťcessaires ŗ l'insertion ŗ l'ťtape i
- Crťation d'une zone triťe en dťbut de tableau dont la taille augmente de un ťlťment ŗ chaque ťtape de traitement
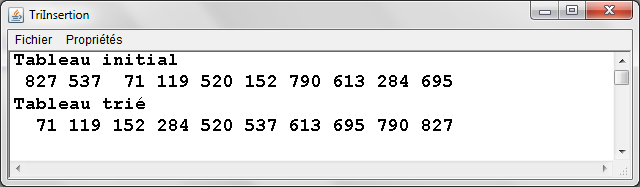
- Exemple : Tri par ordre croissant d'un tableau de 10 entiers
|
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Etape 1 : Insertion de 15 (indice 1) en position 0 dans la liste composťe du seul ťlťment d'indice 0
-> Dťcalage de 16 vers la place libťrťe par le 15
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
15 |
16 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
- Etape 2 : Insertion de 12 (indice 2) en position 0 dans la liste composťe des ťlťments d'indice 0 ŗ 1
-> Dťcalage des valeurs d'indice 0 ŗ 1
|
|
15 |
16 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
12 |
15 |
16 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
- Etape 3 : Insertion de 10 (indice 3) en position 0 dans la liste composťe des ťlťments d'indice 0 ŗ 2
-> Dťcalage des valeurs d'indice 0 ŗ 2
|
|
12 |
15 |
16 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
10 |
12 |
15 |
16 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
- Etape 4 : Insertion de 12 (indice 4) en position 2 dans la liste composťe des ťlťments d'indice 0 ŗ 3
-> Dťcalage des valeurs d'indice 2 ŗ 3
|
|
10 |
12 |
15 |
16 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
10 |
12 |
12 |
15 |
16 |
15 |
19 |
18 |
10 |
16 |
|
|
- Etape 5 : Insertion de 15 (indice 5) en position 4 dans la liste composťe des ťlťments d'indice 0 ŗ 4
-> Dťcalage de la valeur d'indice 4
|
|
10 |
12 |
12 |
15 |
16 |
15 |
19 |
18 |
10 |
16 |
|
|
10 |
12 |
12 |
15 |
15 |
16 |
19 |
18 |
10 |
16 |
|
|
- Etape 6 : Insertion de 19 (indice 6) en position 6 dans la liste composťe des ťlťments d'indice 0 ŗ 5
-> Pas de dťcalage
|
|
10 |
12 |
12 |
15 |
15 |
16 |
19 |
18 |
10 |
16 |
|
|
10 |
12 |
12 |
15 |
15 |
16 |
19 |
18 |
10 |
16 |
|
|
- Etape 7 : Insertion de 18 (indice 7) en position 6 dans la liste composťe des ťlťments d'indice 0 ŗ 6
-> Dťcalage de la valeur d'indice 6
|
|
10 |
12 |
12 |
15 |
15 |
16 |
19 |
18 |
10 |
16 |
|
|
10 |
12 |
12 |
15 |
15 |
16 |
18 |
19 |
10 |
16 |
|
|
- Etape 8 : Insertion de 10 (indice 8) en position 1 dans la liste composťe des ťlťments d'indice 0 ŗ 7
-> Dťcalage des valeurs d'indice 1 ŗ 7
|
|
10 |
12 |
12 |
15 |
15 |
16 |
18 |
19 |
10 |
16 |
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
18 |
19 |
16 |
|
|
- Etape 9 : Insertion de 16 (indice 9) en position 7 dans la liste composťe des ťlťments d'indice 0 ŗ 8
-> Dťcalage des valeurs d'indice 7 ŗ 8
-> Etat final atteint
|
|
10 |
12 |
12 |
12 |
15 |
15 |
16 |
18 |
19 |
16 |
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Rťservation d'un second tableau non nťcessaire
- Utilisation du seul espace mťmoire supplťmentaire nťcessaire ŗ l'opťration d'insertion/dťcalage
Exemple d'exťcution
|
{ Fonction de recherche et retour }
{ de la position d'un entier }
{ dans un tableau d'entiers }
{ triť par ordre croissant }
{ et restreint aux indices 0 a n-1 inclus }
{ (n premiŤres valeurs du tableau) }
{ v : Valeur entiŤre recherchťe }
{ n : Nombre de valeurs initiales du tableau }
{ parmi lesquelles la recherche est rťalisťe }
{ t : Le tableau triť d'entiers de recherche }
entier fonction positionInsertion(-> entier v,
-> entier n,
-> entier [] t)
entier p <- n
faire
p <- p-1
tant que ( ( p >= 0 ) et ( v < t[p] ) )
p <- p+1
retourner p
fin fonction
{ Action de dťcalage de une cellule }
{ vers la droite du contenu des cellules }
{ d'indice indi ŗ indice indf inclus }
{ d'un tableau d'entiers }
{ indi : L'indice initial de dťcalage }
{ indf : L'indice final de dťcalage }
{ t : Le tableau d'entiers oý le dťcalage }
{ est rťalisť }
action decalage(-> entier indi,
-> entier indf,
-> entier [] t ->)
entier i
pour i de indf ŗ indi pas -1 faire
t[i+1] <- t[i]
fait
fin action
{ Action de tri "par insertion" }
{ par ordre croissant des valeurs }
{ contenues dans un tableau d'entiers }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
action triInsertion(-> entier [] t ->)
entier i
entier p
entier v
pour i de 1 ŗ longueur(t)-1 faire
p <- positionInsertion(t[i],i,t)
si p <> i alors
v <- t[i]
decalage(p,i-1,t)
t[p] <- v
fsi
fait
fin action
|
|
TriInsertion.lda |
|
/* Fonction de recherche et retour */
/* de la position d'un int dans un tableau d'int */
/* triť par ordre croissant et restreint */
/* aux indices 0 a n-1 inclus */
/* (n premiŤres valeurs du tableau) */
/* v : Valeur int recherchťe */
/* n : Nombre de valeurs initiales du tableau */
/* parmi lesquelles la recherche est rťalisťe */
/* t : Tableau triť d'entiers de recherche */
static int positionInsertion(int v,int n,int [] t) {
int p = n;
do {
p--; }
while ( ( p >= 0 ) && ( v < t[p] ) );
return p+1;
}
/* Fonction de dťcalage de une cellule */
/* vers la droite du contenu des cellules */
/* d'indice indi ŗ indf inclus */
/* d'un tableau d'int */
/* indi : L'indice initial de dťcalage */
/* indf : L'indice final de dťcalage */
/* t : Le tableau d'int oý le dťcalage */
/* est rťalisť */
static void decalage(int indi,int indf,int [] t) {
for ( int i = indf ; i >= indi ; i-- ) {
t[i+1] = t[i]; }
}
/* Fonction de tri "par insertion" */
/* par ordre croissant des valeurs */
/* contenues dans un tableau d'int */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
static void triInsertion(int [] t) {
for ( int i = 1 ; i < t.length ; i++ ) {
int p = positionInsertion(t[i],i,t);
if ( p != i ) {
int v = t[i];
decalage(p,i-1,t);
t[p] = v; } }
}
|
|
TriInsertion.java - Exemple d'exťcution |
 |
- Quatre types d'ensembles de donnťes testťs pour diffťrentes tailles :
- Ensemble totalement alťatoire
- Ensemble quasiment triť 1 (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Ensemble quasiment triť 2 (ŗ partir de l'ťtat triť, 10% de permutations entre voisins)
- Ensemble dťjŗ triť
|
n |
Sťries alťatoires |
Sťries quasi-triťes nį1 |
Sťries quasi-triťes nį2 |
Sťries triťes |
 |
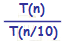
|
|
|
|
|
|
|
|
2 |
0,00000940 |
- |
0,00000686 |
- |
0,00001720 |
- |
0,00000531 |
- |
|
5 |
0,00004530 |
- |
0,00001373 |
- |
0,00004530 |
- |
0,00000718 |
- |
|
10 |
0,00021230 |
- |
0,00007330 |
- |
0,00012330 |
- |
0,00003573 |
- |
|
12 |
0,00028870 |
- |
0,00008110 |
- |
0,00013090 |
- |
0,00004220 |
- |
|
15 |
0,00037500 |
- |
0,00013890 |
- |
0,00016370 |
- |
0,00006240 |
- |
|
20 |
0,00062400 |
- |
0,00026500 |
- |
0,00021220 |
- |
0,00010440 |
- |
|
30 |
0,00129400 |
- |
0,00057700 |
- |
0,00034310 |
- |
0,00015290 |
- |
|
50 |
0,00312000 |
- |
0,00085700 |
- |
0,00046800 |
- |
0,00022780 |
- |
|
70 |
0,00520900 |
- |
0,00187200 |
- |
0,00059300 |
- |
0,00029640 |
- |
|
100 |
0,00968000 |
45,60 |
0,00281000 |
38,34 |
0,00125000 |
10,14 |
0,00041490 |
11,61 |
|
120 |
0,01358000 |
47,04 |
0,00407000 |
50,18 |
0,00219000 |
16,73 |
0,00057700 |
13,67 |
|
150 |
0,02059000 |
54,91 |
0,00701000 |
50,47 |
0,00266000 |
16,25 |
0,00067100 |
10,75 |
|
200 |
0,03479000 |
55,75 |
0,00967000 |
36,49 |
0,00249000 |
11,73 |
0,00095200 |
9,12 |
|
300 |
0,07020000 |
54,25 |
0,01996000 |
34,59 |
0,00608000 |
17,72 |
0,00116900 |
7,65 |
|
500 |
0,19960000 |
63,97 |
0,05320000 |
62,08 |
0,01202000 |
25,68 |
0,00198100 |
8,70 |
|
700 |
0,39010000 |
74,89 |
0,09840000 |
52,56 |
0,02231000 |
37,62 |
0,00290200 |
9,79 |
|
1000 |
0,79600000 |
82,23 |
0,19650000 |
69,93 |
0,03590000 |
28,72 |
0,00425900 |
10,27 |
|
1200 |
1,13420000 |
83,52 |
0,28550000 |
70,15 |
0,04680000 |
21,37 |
0,00497600 |
8,62 |
|
1500 |
1,77210000 |
86,07 |
0,42910000 |
61,21 |
0,07960000 |
29,92 |
0,00686000 |
10,22 |
|
2000 |
3,13710000 |
90,17 |
0,75050000 |
77,61 |
0,09990000 |
40,12 |
0,00827000 |
8,69 |
|
3000 |
7,11300000 |
101,32 |
1,64890000 |
82,61 |
0,21060000 |
34,64 |
0,01092000 |
9,34 |
|
5000 |
19,63900000 |
98,39 |
4,51780000 |
84,92 |
0,57410000 |
47,76 |
0,01810000 |
9,14 |
|
7000 |
37,91000000 |
97,18 |
8,86200000 |
90,06 |
1,04670000 |
46,92 |
0,02869000 |
9,89 |
|
10000 |
78,00000000 |
97,99 |
18,19000000 |
92,57 |
2,19800000 |
61,23 |
0,04009000 |
9,41 |
|
12000 |
113,80000000 |
100,34 |
26,36000000 |
92,33 |
2,80800000 |
60,00 |
0,04852000 |
9,75 |
|
15000 |
172,00000000 |
97,06 |
39,93000000 |
93,06 |
4,46200000 |
56,06 |
0,06230000 |
9,08 |
|
20000 |
310,40000000 |
98,94 |
72,23000000 |
96,24 |
7,80000000 |
78,08 |
0,08260000 |
9,99 |
|
30000 |
706,70000000 |
99,35 |
160,99000000 |
97,63 |
17,06700000 |
81,04 |
0,12180000 |
11,15 |
|
50000 |
1948,30000000 |
99,21 |
445,38000000 |
98,58 |
46,96000000 |
81,80 |
0,20900000 |
11,55 |
|
70000 |
3817,20000000 |
100,69 |
886,20000000 |
100,00 |
92,19000000 |
88,08 |
0,29010000 |
10,11 |
|
100000 |
7769,00000000 |
99,60 |
1815,80000000 |
99,82 |
187,98000000 |
85,52 |
0,42900000 |
10,70 |
|
120000 |
11232,00000000 |
98,70 |
2589,60000000 |
98,24 |
269,90000000 |
96,12 |
0,54600000 |
11,25 |
|
150000 |
17504,00000000 |
101,77 |
4009,30000000 |
100,41 |
422,80000000 |
94,76 |
0,60900000 |
9,78 |
|
200000 |
31184,00000000 |
100,46 |
7188,60000000 |
99,52 |
741,00000000 |
95,00 |
0,90500000 |
10,96 |
|
300000 |
70451,00000000 |
99,69 |
16036,00000000 |
99,61 |
1680,10000000 |
98,44 |
1,07700000 |
8,84 |
|
500000 |
194673,00000000 |
99,92 |
44615,00000000 |
100,17 |
4619,10000000 |
98,36 |
1,90400000 |
9,11 |
|
700000 |
380219,00000000 |
99,61 |
87734,00000000 |
99,00 |
9077,60000000 |
98,47 |
2,70000000 |
9,31 |
|
1000000 |
782387,00000000 |
100,71 |
179338,00000000 |
98,77 |
18443,90000000 |
98,12 |
4,30600000 |
10,04 |
|
1200000 |
1135432,00000000 |
101,09 |
258351,00000000 |
99,76 |
26707,00000000 |
98,95 |
5,10100000 |
9,34 |
|
1500000 |
1891596,00000000 |
108,07 |
405849,00000000 |
101,23 |
41511,00000000 |
98,18 |
6,05300000 |
9,94 |
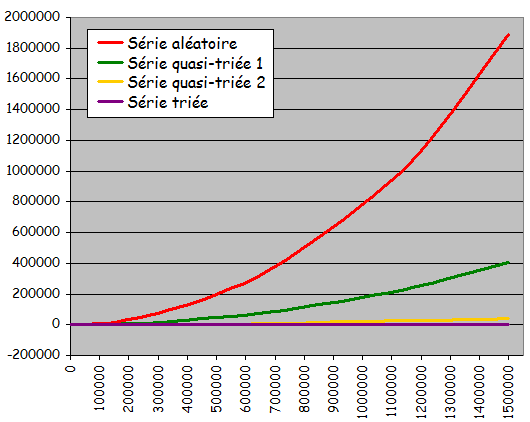
- Rťsultats expťrimentaux :
- Pour les ensembles alťatoires et les ensembles quasi-triťs des 2 types :
- Temps d'exťcution "quadratique" quand la taille de l'ensemble ŗ trier devient grande
-> Temps de tri d'un ensemble n fois plus grand que l'ensemble E ťgal ŗ n2 fois le temps de tri de E
-> Mauvaise scalabilitť
- Trier un ensemble 2 fois plus grand prend 4 fois plus de temps
- Trier un ensemble 10 fois plus grand prend 100 fois plus de temps
- Pour une taille d'ensemble donnťe, tri d'autant plus rapide qu'il est appliquť ŗ des ensembles prťsentant un prť-tri important
- Pour les ensembles dťjŗ triťs :
- Exťcution en temps linťaire et extrÍmement rapide
- Analyse du fonctionnement de l'algorithme :
Dans ce cas particulier :
- Recherche de la position d'insertion trŤs rapide car elle est trouvťe tout de suite
- Jamais de dťcalage car toute valeur insťrťe le serait lŗ oý elle est dťjŗ placťe
-> Pas d'insertion vťritable ni donc de dťcalage
- Amťlioration de l'efficacitť dans le cas gťnťral
- Pas d'opťration de dťcalage cellule aprŤs cellule pour toutes les cellules ŗ dťcaler
- Remplacement par :
- Destruction de la cellule de stockage du tableau lŗ oý un ťlťment disparait
- Crťation, en position d'insertion, d'une autre cellule de stockage pour accueillir la valeur reportťe
- Pas possible sur les tableaux, possible avec des structures de donnťes plus ťlaborťes
- Conclusion
- Mťthode intuitive
- Bonne exploitation des caractťristiques des ensembles
- Pas trŤs simple ŗ implanter
Algorithme de tri par sťlection
- Soit un ensemble de donnťes E
- ProblŤme : Trier cet ensemble selon un critŤre d'ordre total (i.e. tout couple de donnťes est ordonnable selon le critŤre de tri)
- Algorithme de tri par sťlection :
- Rťalisation de n-1 (n = cardinal(E)) ťtapes de traitement numťrotťes i (ŗ partir de 1) :
- Dťtermination de l'indice iMax de l'ťlťment le plus "grand" selon le critŤre de tri prťsent dans le sous-ensemble En-i,
sous-ensemble de E limitť ŗ aux ťlťments d'indice 0 ŗ n-i (les n-i+1 premiers ťlťments)
- Si iMax est diffťrent n-i, permutation de l'ťlťment d'indice iMax avec l'ťlťment d'indice n-i (l'ťlťment en queue de
En-i)
- Crťation d'une zone triťe en fin de tableau dont la taille augmente de un ťlťment ŗ chaque ťtape de traitement
- Exemple : Tri par ordre croissant d'un tableau de 10 entiers
|
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Etape 1 : Sťlection du maximum entre les indices 0 et 8
-> sťlection de 19 en indice 6
-> permutation avec l'ťlťment d'indice 9
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
16 |
15 |
12 |
10 |
12 |
15 |
16 |
18 |
10 |
19 |
|
|
- Etape 2 : Sťlection du maximum entre les indices 0 et 7
-> sťlection de 18 en indice 7
-> permutation avec l'ťlťment d'indice 8
|
|
16 |
15 |
12 |
10 |
12 |
15 |
16 |
18 |
10 |
19 |
|
|
16 |
15 |
12 |
10 |
12 |
15 |
16 |
10 |
18 |
19 |
|
|
- Etape 3 : Sťlection du maximum entre les indices 0 et 6
-> sťlection de 16 en indice 6
-> permutation avec l'ťlťment d'indice 7
|
|
16 |
15 |
12 |
10 |
12 |
15 |
16 |
10 |
18 |
19 |
|
|
16 |
15 |
12 |
10 |
12 |
15 |
10 |
16 |
18 |
19 |
|
|
- Etape 4 : Sťlection du maximum entre les indices 0 et 5
-> sťlection de 16 en indice 0
-> permutation avec l'ťlťment d'indice 6
|
|
16 |
15 |
12 |
10 |
12 |
15 |
10 |
16 |
18 |
19 |
|
|
10 |
15 |
12 |
10 |
12 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 5 : Sťlection du maximum entre les indices 0 et 4
-> sťlection de 15 en indice 5
-> permutation avec l'ťlťment d'indice 5 (pas de permutation)
|
|
10 |
15 |
12 |
10 |
12 |
15 |
16 |
16 |
18 |
19 |
|
|
10 |
15 |
12 |
10 |
12 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 6 : Sťlection du maximum entre les indices 0 et 3
-> sťlection de 15 en indice 1
-> permutation avec l'ťlťment d'indice 4
|
|
10 |
15 |
12 |
10 |
12 |
15 |
16 |
16 |
18 |
19 |
|
|
10 |
12 |
12 |
10 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 7 : Sťlection du maximum entre les indices 0 et 2
-> sťlection de 12 en indice 2
-> permutation avec l'ťlťment d'indice 3
|
|
10 |
12 |
12 |
10 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
10 |
12 |
10 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 8 : Sťlection du maximum entre les indices 0 et 1
-> sťlection de 12 en indice 1
->permutation avec l'ťlťment d'indice 2
|
|
10 |
12 |
10 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 9 : Sťlection du maximum entre les indices 0 et 0
-> sťlection de 10 en indice 0
-> permutation avec l'ťlťment d'indice 1 (pas de permutation)
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
|
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Rťservation d'un second tableau non nťcessaire
- Espace mťmoire supplťmentaire : Celui utilisť pour l'opťration de permutation de deux entiers
Exemple d'exťcution
|
{ Fonction de recherche et retour de l'indice }
{ de la valeur maximale d'un tableau d'entier }
{ restreint ŗ ses n+1 premieres valeurs }
{ n : L'indice inclus jusqu'auquel la recherche }
{ de valeur maximale est rťalisťe }
{ t : Le tableau d'entier oý la recherche }
{ de valeur maximale est rťalisťe }
entier fonction indiceMaximum(-> entier n,
-> entier [] t)
entier iMax <- 0
entier i
pour i de 0 ŗ n faire
si t[i] > t[iMax] alors
iMax <- i
fsi
fait
retourner iMax
fin fonction
{ Action de tri "par selection" }
{ par ordre croissant des valeurs contenues }
{ dans un tableau d'entiers }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
action triSelection(-> entier [] t ->)
entier i
entier aux
entier iMax
entier n <- longueur(t)
pour i de 1 ŗ n-1 faire
iMax <- indiceMaximum(n-i,t)
si iMax <> n-i alors
aux <- t[iMax]
t[iMax] <- t[n-i]
t[n-i] <- aux
fsi
fait
fin action
|
|
TriSelection.lda |
|
/* Fonction de recherche et retour de l'indice */
/* de la valeur maximale d'un tableau d'int */
/* restreint ŗ ses n+1 premieres valeurs */
/* n : L'indice inclus jusqu'auquel la recherche */
/* de valeur maximale est rťalisťe */
/* t : Le tableau d'int oý la recherche */
/* de valeur maximale est rťalisťe */
static int indiceDuMaximum(int n,int [] t) {
int iMax = 0;
for ( int i = 1 ; i <= n ; i++ ) {
if ( t[i] > t[iMax] ) {
iMax = i; } }
return iMax;
}
/* Fonction de tri "par selection" */
/* par ordre croissant des valeurs contenues */
/* dans un tableau d'int */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
static void triSelection(int [] t) {
int n = t.length;
for ( int i = 1 ; i <= n-1 ; i++ ) {
int ind = n-i;
int iMax = indiceDuMaximum(ind,t);
if ( t[iMax] != t[ind] ) {
int aux = t[iMax];
t[iMax] = t[ind];
t[ind] = aux; } }
}
|
|
TriSelection.java - Exemple d'exťcution |
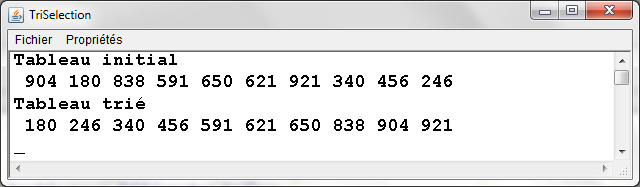 |
- Quatre types d'ensembles de donnťes testťs pour diffťrentes tailles :
- Ensemble totalement alťatoire
- Ensemble quasiment triť 1 (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Ensemble quasiment triť 2 (ŗ partir de l'ťtat triť, 10% de permutations entre voisins)
- Ensemble dťjŗ triť
- Rťsultats expťrimentaux :
- Temps quadratique fonction de la taille de l'ensemble ŗ trier
- Temps d'exťcution trŤs voisins pour les 4 types d'ensembles
- Algorithme non intťressant si l'ensemble ŗ trier peut ťventuellement Ítre dťjŗ triť ou partiellement triť
- Conclusion
- Pas d'exploitation des caractťristiques des ensembles
- Assez simple ŗ implanter
Algorithme de tri ŗ bulle
- Basť sur l'opťration consistant ŗ permuter deux composantes
- Soit un ensemble de donnťes E
- ProblŤme : Trier cet ensemble selon un critŤre d'ordre total (i.e. tout couple de donnťes est ordonnable selon le critŤre de tri)
- Algorithme de tri ŗ bulle :
- Rťalisation de n-1 (n = cardinal(E)) ťtapes de traitement numťrotťes i (ŗ partir de 0) consistant ŗ traiter le sous-ensemble Ei de E
limitť ŗ ses n-i premiŤres valeurs :
- Parcours sťquentiel des n-i-1 couples de valeurs contiguŽs de Ei
- Permutation de ces deux valeurs si elles ne respectent pas le critŤre de tri
- Crťation d'une zone triťe en fin de tableau dont la taille augmente de un ťlťment ŗ chaque ťtape de traitement
- Telles des bulles montant vers la surface d'un liquide, ŗ chaque ťtape, dťportation des "grandes" valeurs vers la fin du tableau
restant ŗ trier avec report ŗ chaque ťtape de la plus "grande" en fin de tableau
- Exemple : Tri par ordre croissant d'un tableau de 10 entiers
|
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Etape 0 : Parcours des 9 premiers couples d'entiers et permutation des 2 entiers s'ils ne sont pas correctement ordonnťs (7 permutations)
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
15 |
16 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
15 |
12 |
16 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
15 |
12 |
10 |
16 |
12 |
15 |
19 |
18 |
10 |
16 |
|
|
15 |
12 |
10 |
12 |
16 |
15 |
19 |
18 |
10 |
16 |
|
|
15 |
12 |
10 |
12 |
15 |
16 |
19 |
18 |
10 |
16 |
|
|
15 |
12 |
10 |
12 |
15 |
16 |
19 |
18 |
10 |
16 |
|
|
15 |
12 |
10 |
12 |
15 |
16 |
18 |
19 |
10 |
16 |
|
|
15 |
12 |
10 |
12 |
15 |
16 |
18 |
10 |
19 |
16 |
|
|
15 |
12 |
10 |
12 |
15 |
16 |
18 |
10 |
16 |
19 |
|
|
15 |
12 |
10 |
12 |
15 |
16 |
18 |
10 |
16 |
19 |
|
|
- Etape 1 : Parcours des n-2 premiers couples (6 permutations)
|
|
12 |
10 |
12 |
15 |
16 |
15 |
10 |
16 |
18 |
19 |
|
|
- Etape 2 : Parcours des n-3 premiers couples (3 permutations)
|
|
10 |
12 |
12 |
15 |
15 |
10 |
16 |
16 |
18 |
19 |
|
|
- Etape 3 : Parcours des n-4 premiers couples (1 permutation)
|
|
10 |
12 |
12 |
15 |
10 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 4 : Parcours des n-5 premiers couples (1 permutation)
|
|
10 |
12 |
12 |
10 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 5 : Parcours des n-6 premiers couples (1 permutation)
|
|
10 |
12 |
10 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 6 : Parcours des n-7 premiers couples (1 permutation)
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 7 : Parcours des n-8 premiers couples (0 permutation)
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
- Etape 8 : Parcours des n-9 premiers couples (0 permutation)
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
|
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
Exemple d'exťcution
|
{ Action de tri ŗ bulle par ordre croissant }
{ des valeurs contenues }
{ dans un tableau d'entiers }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
action triBulle(-> entier [] t ->)
entier i
entier j
entier aux
pour i de 0 ŗ longueur(t)-2 faire
pour j de 0 ŗ longueur(t)-2-i faire
si t[j] > t[j+1] alors
aux <- t[j]
t[j] <- t[j+1]
t[j+1] <- aux
fsi
fait
fait
fin action
|
|
TriBulle.lda |
|
/* Fonction de tri ŗ bulle par ordre croissant */
/* des valeurs contenues dans un tableau d'int */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
static void triBulle(int [] t) {
int n = t.length;
for ( int i = 0 ; i < n-1 ; i++ ) {
for ( int j = 0 ; j < n-i-1 ; j++ ) {
if ( t[j] > t[j+1] ) {
int aux = t[j];
t[j] = t[j+1];
t[j+1] = aux; } } }
}
|
|
TriBulle.java - Exemple d'exťcution |
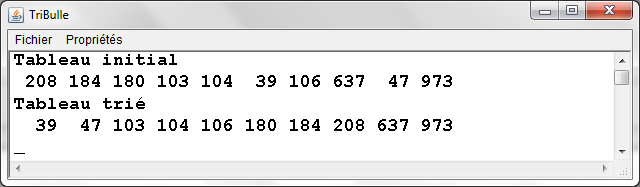 |
- Optimisation classique de l'algorithme de tri ŗ bulle :
- Exploitation du fait qu'il n'est pas rare qu'il ne soit pas nťcessaire d'effectuer n-1 ťtapes de recherche de permutations
- Si, lors d'une ťtape, aucune permutation rťalisťe
-> Tableau triť
-> Plus nťcessaire de continuer ŗ chercher des permutations
-> On arrÍte.
|
{ Action de tri ŗ bulle par ordre croissant }
{ des valeurs contenues }
{ dans un tableau d'entiers }
{ Version optimisťe }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
action triBulleOptimise(-> entier [] t ->)
entier j
entier aux
booleen permutation
entier np <- longueur(t)-1
faire
permutation <- faux
pour j de 0 ŗ np-1 faire
si t[j] > t[j+1] alors
aux <- t[j]
t[j] <- t[j+1]
t[j+1] <- aux
permutation <- vrai
fsi
fait
np <- np-1
tantque permutation == vrai
fin action
|
|
TriBulleOptimise.lda |
|
/* Fonction de tri ŗ bulle par ordre croissant */
/* des valeurs contenues dans un tableau d'int */
/* Version optimisťe */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
static void triBulleOptimise(int [] t) {
boolean permutation;
int np = t.length-1;
do {
permutation = false;
for ( int j = 0 ; j < np ; j++ ) {
if ( t[j] > t[j+1] ) {
int aux = t[j];
t[j] = t[j+1];
t[j+1] = aux;
permutation = true; } }
np--; }
while ( permutation ) ;
}
|
|
TriBulleOptimise.java - Exemple d'exťcution |
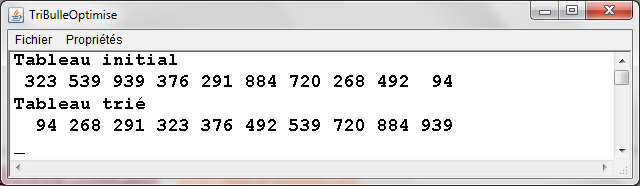 |
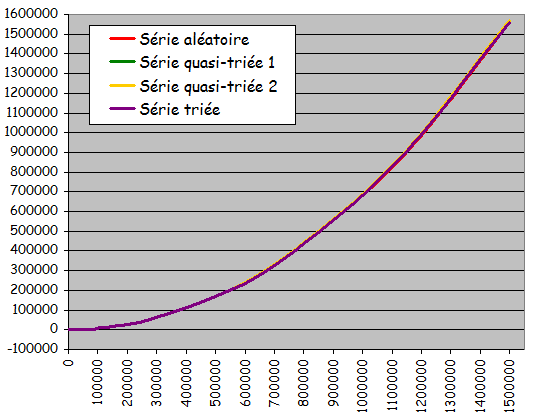
- Quatre types d'ensembles de donnťes testťs pour diffťrentes tailles :
- Ensemble totalement alťatoire
- Ensemble quasiment triť 1 (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Ensemble quasiment triť 2 (ŗ partir de l'ťtat triť, 10% de permutations entre voisins immťdiats)
- Ensemble dťjŗ triť
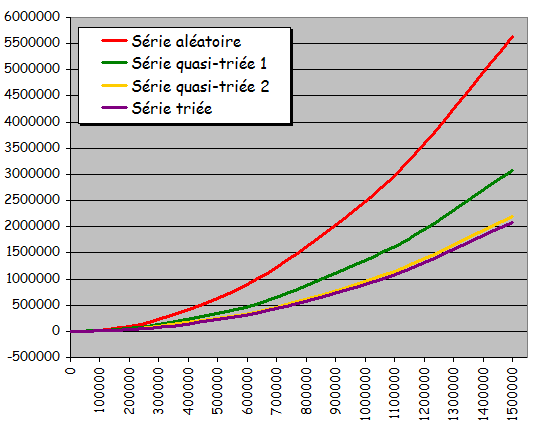
Tri ŗ bulle sans optimisation
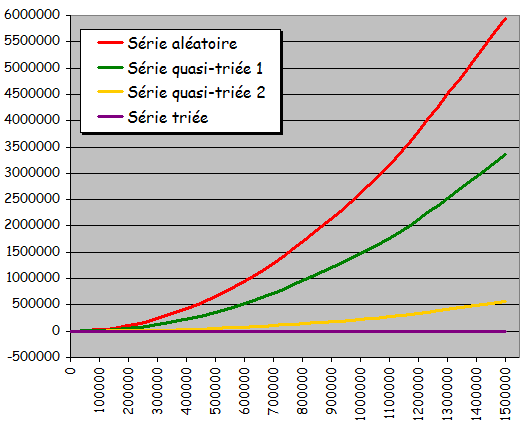
Tri ŗ bulle avec optimisation
- Rťsultats expťrimentaux :
- Temps quadratique de la taille de l'ensemble ŗ trier
- Exploitation d'une prť-organisation ťventuelle de l'ensemble ŗ trier pour accťlťrer le traitement
- Version optimisťe plus intťressante dans ce cadre (temps d'exťcution quasi-instantanť pour les ensembles triťs)
- Conclusion
- Assez bonne exploitation des caractťristiques des ensembles
- TrŤs simple ŗ implanter
Algorithme de tri par fusion
- Algorithmes prťcťdents gravement dťficients :
- Inadaptťs au tri d'ensembles de donnťes de cardinal trŤs important
- Pratiquement inemployables car trop lents au delŗ d'une certaine taille d'ensemble (temps quadratique de la taille de l'ensemble)
- Existence d'une autre catťgorie d'algorithmes de tri basťe sur le rťflexe naturel que nous avons tous quand il s'agit d'effectuer
un tri sur un tas de donnťes de taille importante :
- Diviser le tas en 2 (ou plusieurs) tas ťlťmentaires
- Trier ces 2 (ou plus) tas
- Fusionner les tas ťlťmentaires triťs ainsi obtenus de maniŤre rapide en exploitant le fait qu'ils sont tous deux (tous) triťs
- Si subdivision en 2 tas -> Mťthode dichotomique
- Algorithme de tri par fusion :
- Subdivision de l'ensemble E ŗ trier en 2 sous-ensembles de tailles aussi identiques que possible
- Tri de chacun des 2 sous-ensembles par le mÍme principe algorithmique de subdivision
- Fusion des deux sous-ensembles triťs en un seul ensemble triť
- Exemple : Tri par ordre croissant d'un tableau de 10 entiers
- Tableau initial d'indices 0 ŗ 9
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Subdivision en 2 sous-tableaux d'indices 0 ŗ 4 et 5 ŗ 9
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Subdivision du sous-tableau 0 ŗ 4 en 2 sous-tableaux d'indices 0 ŗ 1 et 2 ŗ 4
- Subdivision du sous-tableau 5 ŗ 9 en 2 sous-tableaux d'indices 5 ŗ 6 et 7 ŗ 9
|
|
16 |
15 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Le sous-tableau 0 ŗ 1 a 2 valeurs. Soit il est dťjŗ triť. Soit il ne l'est pas et on le trie en une permutation.
- Subdivision du sous-tableau 2 ŗ 4 en 2 sous-tableaux d'indices 2 ŗ 2 et 3 ŗ 4
- Le sous-tableau 5 ŗ 6 a 2 valeurs. Soit il est dťjŗ triť. Soit il ne l'est pas et on le trie en une permutation.
- Subdivision du sous-tableau 7 ŗ 9 en 2 sous-tableaux d'indices 7 ŗ 7 et 8 ŗ 9
|
|
15 |
16 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Le sous-tableau 0 ŗ 1 est triť.
- Le sous-tableau 2 ŗ 2 est triť.
- Le sous-tableau 3 ŗ 4 a 2 valeurs. Soit il est dťjŗ triť. Soit il ne l'est pas et on le trie en une permutation.
- Le sous-tableau 5 ŗ 6 est triť.
- Le sous-tableau 7 ŗ 7 est triť.
- Le sous-tableau 8 ŗ 9 a 2 valeurs. Soit il est dťjŗ triť. Soit il ne l'est pas et on le trie en une permutation.
-> Tous les sous-tableaux sont triťs.
-> On fusionne dans l'ordre inverse des subdivisions.
|
|
15 |
16 |
12 |
10 |
12 |
15 |
19 |
18 |
10 |
16 |
|
- Fusion des sous-tableaux 2 ŗ 2 et 3 ŗ 4
- Fusion des sous-tableaux 7 ŗ 7 et 8 ŗ 9
|
|
15 |
16 |
10 |
12 |
12 |
15 |
19 |
10 |
16 |
18 |
|
- Fusion des sous-tableaux 0 ŗ 1 et 2 ŗ 4
- Fusion des sous-tableaux 5 ŗ 6 et 7 ŗ 9
|
|
10 |
12 |
12 |
15 |
16 |
10 |
15 |
16 |
18 |
19 |
|
- Etat final aprŤs fusion des sous-tableaux 0 ŗ 4 et 5 ŗ 9
|
|
10 |
10 |
12 |
12 |
15 |
15 |
16 |
16 |
18 |
19 |
|
|
Exemple d'exťcution
- Implantation du tri par fusion pas spťcialement complexe mais grandement facilitťe par l'utilisation d'une mťthode de programmation non
encore abordťe : la rťcursivitť
- Pas de description prťcise ici
|
{ Action de fusion en un tableau triť }
{ de deux sous-tableaux contigus triťs }
{ dťfinis au sein d'un tableau d'entiers }
{ Le sous-tableau 1 contient les t1 entiers }
{ situťs ŗ partir de l'indice i1 }
{ Le sous-tableau 2 contient les t2 entiers }
{ situťs ŗ partir de l'indice i1+t1 }
{ t : Le tableau d'entiers contenant }
{ les deux sous-tableaux contigus }
{ i1 : L'indice dans t du premier entier }
{ du premier sous-tableau }
{ t1 : Le nombre d'entiers du premier sous-tableau }
{ t2 : Le nombre d'entiers du second sous-tableau }
action fusion(-> entier [] t ->,
-> entier i1,
-> entier t1,
-> entier t2)
entier deb <- i1
entier i2 <- i1+t1
entier l <- t1+t2
entier l1 <- i1+t1
entier l2 <- l1+t2
entier [l] tf
entier i
pour i de 0 ŗ l-1 faire
si i1 == l1 alors
tf[i] <- t[i2]
i2 <- i2+1
sinon
si i2 == l2 alors
tf[i] <- t[i1]
i1 <- i1+1
sinon
si t[i1] < t[i2] alors
tf[i] <- t[i1]
i1 <- i1+1
sinon
tf[i] <- t[i2]
i2 <- i2+1
fsi
fsi
fsi
fait
pour i de 0 ŗ l-1 faire
t[deb+i] <- tf[i]
fait
fin action
{ Action de tri par fusion par ordre croissant }
{ d'un tableau d'entiers des indices indi }
{ ŗ indf compris }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
{ indi : L'indice initial des valeurs ŗ trier }
{ indf : L'indice final des valeurs ŗ trier }
action triFusion(-> entier [] t ->,
-> entier indi,
-> entier indf)
entier nbVal <- indf-indi+1
entier iMedian
entier aux
si nbVal > 1 alors
si nbVal == 2 alors
si t[indf] < t[indi] alors
aux <- t[indi]
t[indi] <- t[indf]
t[indf] <- aux
fsi
sinon
iMedian <- (indi+indf)/2
triFusion(t,indi,iMedian)
triFusion(t,iMedian+1,indf)
fusion(t,indi,iMedian-indi+1,indf-iMedian)
fsi
fsi
fin action
{ Action de tri par fusion par ordre croissant }
{ d'un tableau d'entiers }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
action triFusion(-> entier [] t ->)
triFusion(t,0,longueur(t)-1)
fin action
|
|
TriFusion.lda |
|
/* Action de fusion en un tableau triť */
/* de deux sous-tableaux contigus triťs */
/* dťfinis au sein d'un tableau d'entiers */
/* Le sous-tableau 1 contient les t1 entiers */
/* situťs ŗ partir de l'indice i1 */
/* Le sous-tableau 2 contient les t2 entiers */
/* situťs ŗ partir de l'indice i1+t1 */
/* t : Le tableau d'entiers contenant */
/* les deux sous-tableaux contigus */
/* i1 : L'indice dans t du premier entier */
/* du premier sous-tableau */
/* t1 : Le nombre d'entiers du premier sous-tableau */
/* t2 : Le nombre d'entiers du second sous-tableau */
static void fusion(int [] t,int i1,int t1,int t2) {
int deb = i1;
int i2 = i1+t1;
int l = t1+t2;
int l1 = i1+t1;
int l2 = l1+t2;
int [] tf = new int[l];
for ( int i = 0 ; i < l ; i++ ) {
if ( i1 == l1 ) {
tf[i] = t[i2];
i2++; }
else {
if ( i2 == l2 ) {
tf[i] = t[i1];
i1++; }
else {
if ( t[i1] < t[i2] ) {
tf[i] = t[i1];
i1++; }
else {
tf[i] = t[i2];
i2++; } } } }
for ( int i = 0 ; i < l ; i++ ) {
t[deb+i] = tf[i]; }
}
/* Fonction de tri par fusion */
/* par ordre croissant d'un tableau d'entiers */
/* des indices indi a indf compris */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
/* indi : L'indice initial des valeurs ŗ trier */
/* indf : L'indice final des valeurs ŗ trier */
static void triFusion(int [] t,int indi,int indf) {
int nbVal = indf-indi+1;
if ( nbVal > 1 ) {
if ( nbVal == 2 ) {
if ( t[indf] < t[indi] ) {
int aux = t[indi];
t[indi] = t[indf];
t[indf] = aux; } }
else {
int iMedian =(indi+indf)/2;
triFusion(t,indi,iMedian);
triFusion(t,iMedian+1,indf);
fusion(t,indi,iMedian-indi+1,indf-iMedian); } }
}
/* Fonction de tri par fusion */
/* par ordre croissant d'un tableau d'int */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
static void triFusion(int [] t) {
triFusion(t,0,t.length-1);
}
|
|
TriFusion.java - Exemple d'exťcution |
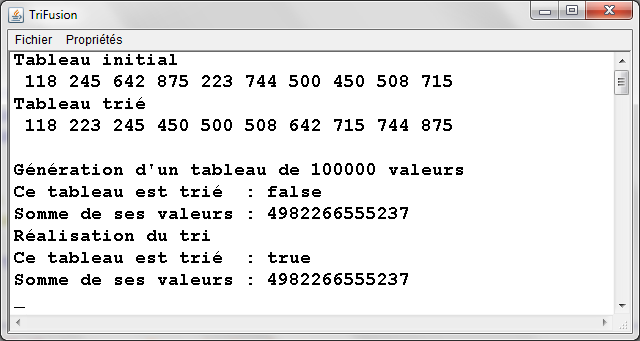 |
- Quatre types d'ensembles de donnťes testťs pour diffťrentes tailles :
- Ensemble totalement alťatoire
- Ensemble quasiment triť 1 (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Ensemble quasiment triť 2 (ŗ partir de l'ťtat triť, 10% de permutations entre voisins)
- Ensemble dťjŗ triť
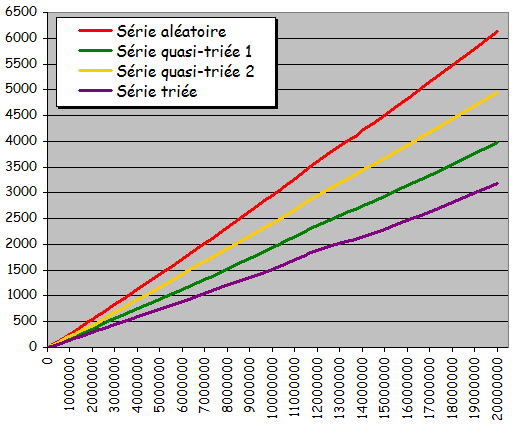
- Rťsultats expťrimentaux :
- Courbes trŤs diffťrentes des courbes obtenues jusqu'ici pour les tris non dichotomiques :
- Courbes non quadratiques
- Forte ressemblance avec des droites
- Tri possible d'ensembles beaucoup plus grands en obtenant des temps d'exťcution considťrablement plus courts
- Exploitation effective d'une prť-organisation de l'ensemble pour sensiblement accťlťrer le traitement
Tri rapide (Quick Sort)
- Algorithme du "QuickSort" (tri rapide) gťnťralement employť quand il s'agit d'obtenir les meilleures performances
- Basť sur le principe "diviser pour rťgner"
- Technique de subdivision du QuickSort un peu plus ťlaborťe que celle du tri par fusion
- But : Eviter d'avoir ŗ rťaliser la phase de fusion
- Ordonnement des sous-tableaux gauche et droit l'un par rapport ŗ l'autre (i.e. la valeur "maximale" ŗ gauche est plus "petite"
que la valeur "minimale" ŗ droite) avant de basculer vers la phase de tri de ces deux sous-tableaux
-> Plus besoin de les fusionner
- Phase de subdivision :
- Dťtermination d'un pivot
- Sťlection de toutes les valeurs plus petites que le pivot et placement de ces valeurs ŗ gauche pour dťfinir le sous-tableau gauche
- Sťlection de toutes les valeurs plus grandes que le pivot et placement de ces valeurs ŗ droite pour dťfinir le sous-tableau droit
- Nouvel indice de la valeur pivot : Limite entre les sous-tableaux gauche et droit
- Utilisation de l'algorithme de tri rapide sur les sous-tableaux gauche et droit pour les trier selon le mÍme principe
- Mťthode de choix du pivot : Un des moyens offert au dťveloppeur pour optimiser le fonctionnement (ťventuellement dans le cadre d'ensembles
prťsentant certaines caractťristiques)
- Techniques classiques :
- Choisir la premiŤre valeur
- Choisir la derniŤre valeur
- Choisir la valeur d'indice mťdian
- Choisir la moyenne des valeurs minimales et maximales du tableau
- Pivot -> la valeur maximale du sous-tableau gauche et valeur minimale du sous-tableau droit
Exemple d'exťcution
|
{ Fonction de reorganisation d'un tableau t }
{ d'entiers des indices indi a indf inclus }
{ par replaÁage ŗ gauche de toutes les valeurs }
{ plus petites que t[pivot], ŗ droite de toutes }
{ les valeur plus grande que t[pivot] }
{ et au centre de toutes les valeurs egales }
{ ŗ t[pivot] }
{ Retourne l'indice de la valeur d'indice }
{ maximum, apres replaÁage, de toutes }
{ les valeurs ťgales ŗ t[pivot] }
entier fonction pivotage(-> entier [] t ->,
-> entier indi,
-> entier indf,
-> entier pivot)
entier i
entier j <- indi
entier aux <- t[pivot]
t[pivot] <- t[indf]
t[indf] <- aux
pour i de indi ŗ indf-1 faire
si t[i] <= t[indf] alors
aux <- t[i]
t[i] <- t[j]
t[j] <- aux
j <- j+1
fsi
fait
aux <- t[indf]
t[indf] <- t[j]
t[j] <- aux
retourner j
fin fonction
{ Action de tri rapide par ordre croissant }
{ d'un tableau d'entiers des indices indi }
{ ŗ indf compris }
{ Mťthode de choix du pivot : Valeur situťe }
{ ŗ l'indice moyen de indi et indf }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
{ indi : L'indice initial des valeurs ŗ trier }
{ indf : L'indice final des valeurs ŗ trier }
action triRapide(-> entier [] t ->,
-> entier indi,
-> entier indf)
entier iMedian
entier aux
entier pivot
entier nbVal <- indf-indi+1
si nbVal > 1 alors
si nbVal == 2 alors
si t[indf] < t[indi] alors
aux <- t[indi]
t[indi] <- t[indf]
t[indf] <- aux
fsi
sinon
pivot <- (indi+indf)/2
iMedian <- pivotage(t,indi,indf,pivot)
triRapide(t,indi,iMedian-1)
triRapide(t,iMedian+1,indf)
fsi
fsi
fin action
{ Action de tri rapide par ordre croissant }
{ d'un tableau d'entiers }
{ Pivot choisi : Valeur mťdiane du tableau }
{ t : Le tableau d'entiers ŗ trier }
{ par ordre croissant }
action triRapide(-> entier [] t ->)
triRapide(t,0,longueur(t)-1)
fin action
|
|
TriRapide.lda |
|
/* Fonction de reorganisation d'un tableau */
/* d'entiers des indices indi a indf inclus */
/* par replacage a gauche de toutes les valeurs */
/* plus petites que t[pivot], a droite de toutes */
/* les valeurs plus grandes que t[pivot] */
/* et au centre de toutes les valeurs egales */
/* a t[pivot] */
/* Retourne l'indice de la valeur d'indice */
/* maximum, apres replacage, de toutes */
/* les valeurs egales a t[pivot] */
static int pivotage(int [] t,int indi,int indf,int pivot) {
int j = indi;
int aux = t[pivot];
t[pivot] = t[indf];
t[indf] = aux;
for ( int i = indi ; i < indf ; i++ ) {
if ( t[i] <= t[indf] ) {
if ( i != j ) {
aux = t[i];
t[i] = t[j];
t[j] = aux; }
j++; } }
if ( indf != j ) {
aux = t[indf];
t[indf] = t[j];
t[j] = aux; }
return j;
}
/* Fonction de tri rapide par ordre croissant */
/* d'un tableau d'int des indices */
/* indi a indf compris */
/* Mťthode de choix du pivot : Valeur situťe */
/* ŗ l'indice moyen de indi et indf */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
/* indi : L'indice initial des valeurs ŗ trier */
/* indf : L'indice final des valeurs ŗ trier */
static void triRapide(int [] t,int indi,int indf) {
int nbVal = indf-indi+1;
if ( nbVal > 1 ) {
if ( nbVal == 2 ) {
if ( t[indf] < t[indi] ) {
int aux = t[indi];
t[indi] = t[indf];
t[indf] = aux; } }
else {
int pivot = (indi+indf)>>1;
int iMedian = pivotage(t,indi,indf,pivot);
triRapide(t,indi,iMedian-1);
triRapide(t,iMedian+1,indf); } }
}
/* Fonction de tri rapide par ordre croissant */
/* d'un tableau d'int */
/* Pivot choisi : Valeur mťdiane du tableau */
/* t : Le tableau d'int ŗ trier */
/* par ordre croissant */
static void triRapide(int [] t) {
triRapide(t,0,t.length-1);
}
|
|
TriRapide.java - Exemple d'exťcution |
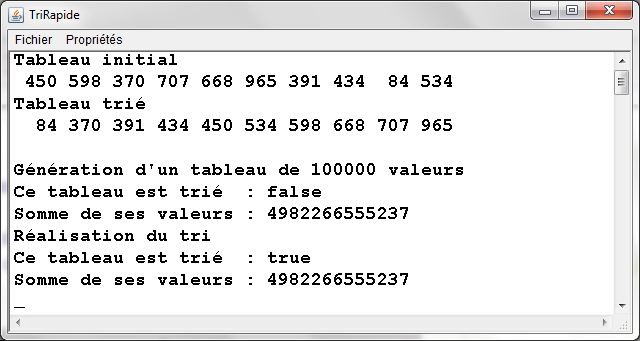 |
- Quatre types d'ensembles de donnťes testťs pour diffťrentes tailles :
- Ensemble totalement alťatoire
- Ensemble quasiment triť 1 (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Ensemble quasiment triť 2 (ŗ partir de l'ťtat triť, 10% de permutations entre voisins)
- Ensemble dťjŗ triť
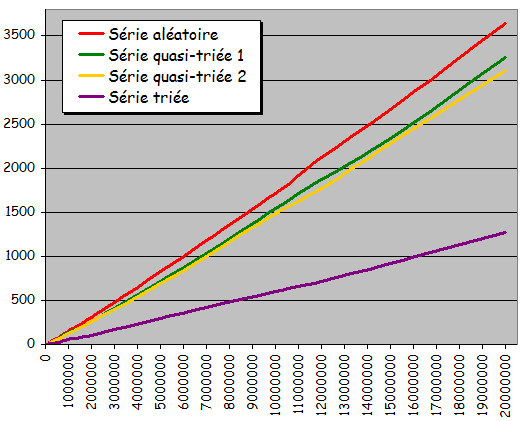
|
n |
Sťries alťatoires |
Sťries quasi-triťes nį1 |
Sťries quasi-triťes nį2 |
Sťries triťes |
|
|
|
|
|
|
|
|
|
|
2 |
0,00000170 |
- |
0,00000296 |
- |
0,00000328 |
- |
0,00000211 |
- |
|
5 |
0,00005620 |
- |
0,00002262 |
- |
0,00005227 |
- |
0,00001794 |
- |
|
10 |
0,00025120 |
- |
0,00012574 |
- |
0,00015398 |
- |
0,00007629 |
- |
|
12 |
0,00032600 |
- |
0,00016700 |
- |
0,00021530 |
- |
0,00010936 |
- |
|
15 |
0,00044770 |
- |
0,00020280 |
- |
0,00028550 |
- |
0,00016380 |
- |
|
20 |
0,00065200 |
- |
0,00039780 |
- |
0,00045080 |
- |
0,00024330 |
- |
|
30 |
0,00113720 |
- |
0,00073940 |
- |
0,00070670 |
- |
0,00040560 |
- |
|
50 |
0,00218400 |
- |
0,00137590 |
- |
0,00127460 |
- |
0,00074730 |
- |
|
70 |
0,00330720 |
- |
0,00217470 |
- |
0,00196500 |
- |
0,00117460 |
- |
|
100 |
0,00508090 |
20,23 |
0,00346400 |
27,55 |
0,00338500 |
21,98 |
0,00181000 |
23,73 |
|
120 |
0,00652000 |
20,00 |
0,00455500 |
27,28 |
0,00394700 |
18,33 |
0,00247900 |
22,67 |
|
150 |
0,00814200 |
18,19 |
0,00608400 |
30,00 |
0,00546000 |
19,12 |
0,00310400 |
18,95 |
|
200 |
0,01154600 |
17,71 |
0,00809800 |
20,36 |
0,00776800 |
17,23 |
0,00432100 |
17,76 |
|
300 |
0,01940600 |
17,06 |
0,01404000 |
18,99 |
0,01224600 |
17,33 |
0,00717600 |
17,69 |
|
500 |
0,03494000 |
16,00 |
0,02489800 |
18,10 |
0,02268200 |
17,80 |
0,01282300 |
17,16 |
|
700 |
0,05118000 |
15,48 |
0,03755000 |
17,27 |
0,03433000 |
17,47 |
0,01862600 |
15,86 |
|
1000 |
0,07428000 |
14,62 |
0,05797000 |
16,73 |
0,05478000 |
16,18 |
0,02714000 |
14,99 |
|
1200 |
0,09360000 |
14,36 |
0,07160000 |
15,72 |
0,06270000 |
15,89 |
0,03478000 |
14,03 |
|
1500 |
0,11860000 |
14,57 |
0,09219000 |
15,15 |
0,08252000 |
15,11 |
0,04368000 |
14,07 |
|
2000 |
0,16660000 |
14,43 |
0,12917000 |
15,95 |
0,12044000 |
15,50 |
0,06193000 |
14,33 |
|
3000 |
0,26084000 |
13,44 |
0,20389000 |
14,52 |
0,18250000 |
14,90 |
0,09200000 |
12,82 |
|
5000 |
0,47740000 |
13,66 |
0,36005000 |
14,46 |
0,33860000 |
14,93 |
0,17320000 |
13,51 |
|
7000 |
0,68640000 |
13,41 |
0,54610000 |
14,54 |
0,52580000 |
15,32 |
0,24960000 |
13,40 |
|
10000 |
1,00470000 |
13,53 |
0,80040000 |
13,81 |
0,76130000 |
13,90 |
0,36040000 |
13,28 |
|
12000 |
1,21050000 |
12,93 |
0,98590000 |
13,77 |
0,93760000 |
14,95 |
0,41800000 |
12,02 |
|
15000 |
1,59110000 |
13,42 |
1,22160000 |
13,25 |
1,19350000 |
14,46 |
0,57720000 |
13,21 |
|
20000 |
2,20900000 |
13,26 |
1,71450000 |
13,27 |
1,57240000 |
13,06 |
0,76440000 |
12,34 |
|
30000 |
3,43510000 |
13,17 |
2,71600000 |
13,32 |
2,64260000 |
14,48 |
1,18560000 |
12,89 |
|
50000 |
5,94040000 |
12,44 |
4,75640000 |
13,21 |
4,61290000 |
13,62 |
2,05300000 |
11,85 |
|
70000 |
8,56290000 |
12,48 |
6,81800000 |
12,48 |
6,80100000 |
12,93 |
3,06380000 |
12,27 |
|
100000 |
12,60010000 |
12,54 |
10,20200000 |
12,75 |
10,07700000 |
13,24 |
4,38360000 |
12,16 |
|
120000 |
15,35050000 |
12,68 |
12,35500000 |
12,53 |
12,30800000 |
13,13 |
5,40080000 |
12,92 |
|
150000 |
19,26600000 |
12,11 |
16,09900000 |
13,18 |
15,58400000 |
13,06 |
6,89500000 |
11,95 |
|
200000 |
27,28500000 |
12,35 |
21,76200000 |
12,69 |
19,50000000 |
12,40 |
9,29140000 |
12,16 |
|
300000 |
40,57600000 |
11,81 |
33,99200000 |
12,52 |
32,30000000 |
12,22 |
14,57040000 |
12,29 |
|
500000 |
71,35500000 |
12,01 |
59,53000000 |
12,52 |
59,90000000 |
12,99 |
25,04120000 |
12,20 |
|
700000 |
102,83500000 |
12,01 |
86,10000000 |
12,63 |
82,99000000 |
12,20 |
36,00500000 |
11,75 |
|
1000000 |
149,99400000 |
11,90 |
126,99000000 |
12,45 |
121,36000000 |
12,04 |
52,93380000 |
12,08 |
|
1200000 |
181,14800000 |
11,80 |
155,53000000 |
12,59 |
148,20000000 |
12,04 |
65,00520000 |
12,04 |
|
1500000 |
227,15200000 |
11,79 |
196,87000000 |
12,23 |
189,60000000 |
12,17 |
77,61000000 |
11,26 |
|
2000000 |
310,12800000 |
11,37 |
264,73000000 |
12,16 |
260,55000000 |
13,36 |
106,70100000 |
11,48 |
|
3000000 |
478,48400000 |
11,79 |
413,41000000 |
12,16 |
397,85000000 |
12,32 |
168,64000000 |
11,57 |
|
5000000 |
824,68000000 |
11,56 |
718,37500000 |
12,07 |
688,75000000 |
11,50 |
289,54000000 |
11,56 |
|
7000000 |
1179,40900000 |
11,47 |
1033,52500000 |
12,00 |
1003,05000000 |
12,09 |
416,55000000 |
11,57 |
|
10000000 |
1717,32800000 |
11,45 |
1538,15000000 |
12,11 |
1482,00000000 |
12,21 |
606,05000000 |
11,45 |
|
12000000 |
2126,25900000 |
11,74 |
1870,42500000 |
12,03 |
1769,05000000 |
11,94 |
713,22000000 |
10,97 |
|
15000000 |
2663,34600000 |
11,72 |
2331,80000000 |
11,84 |
2276,80000000 |
12,01 |
916,32000000 |
11,81 |
|
20000000 |
3644,20000000 |
11,75 |
3250,25000000 |
12,28 |
3103,65000000 |
11,91 |
1273,75000000 |
11,94 |
- Rťsultats expťrimentaux
- Courbes de temps d'exťcution de mÍme aspect linťaire que les courbes du tri par fusion (rassurant car mÍme technique algorithmique de dťcomposition)
- Attention! Rapports T(n)/T(n/10) quasi-systťmatiquement supťrieurs ŗ 10.0
-> Rapports peu compatibles avec l'hypothŤse de linťaritť car attendus voisins de 10.0 en cas de linťaritť
- Ici aussi, temps d'exťcution raccourcis si prť-organisation de l'ensemble ŗ trier
Performances comparťes
- Comparaison des temps d'exťcution respectifs des diffťrents algorithmes sur les diffťrents ensembles testťs
- ATTENTION! A considťrer avec prudence car de simples diffťrences d'implantation des algorithmes pourraient avoir pour consťquence un changement
des rťsultats et donc d'interprťtation
- Comparaison des tris par insertion, par sťlection, ŗ bulle et ŗ bulle optimisť
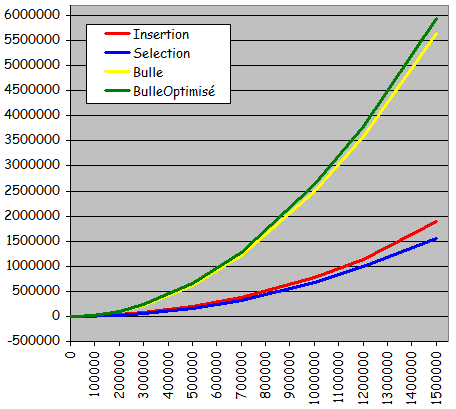
Temps de tri pour des sťries totalement alťatoires
- Tris par sťlection et par insertion de performances voisines avec un lťger avantage au tri par sťlection
- Tris ŗ bulle sans et avec optimisation eux aussi de performances voisines avec un lťger malus pour la version optimisťe!
Non compensation des calculs ťconomisťs par l'optimisation par les calculs consentis pour l'implantation de l'optimisation
- Tris ŗ bulle peu performants par rapport au 2 autres mťthodes de tri : PrŤs de 4 fois moins rapides
- Sťries quasi-triťes (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
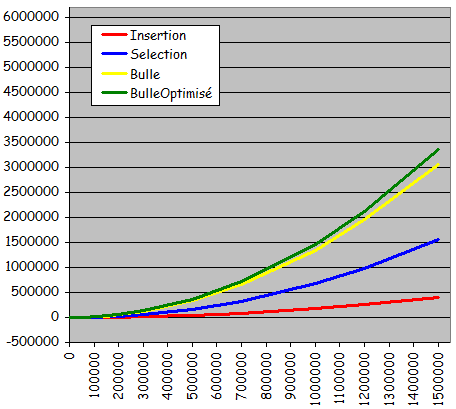
Temps de tri pour des sťries quasi-triťes
(ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Performances en progression sauf pour le tri par sťlection qui reste inchangť
- Le tri ŗ bulle optimisť toujours non intťressant par rapport au tri ŗ bulle sans optimisation
- Le tri par insertion : Devient le plus rapide
- Sťries quasi-triťes (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs voisines)
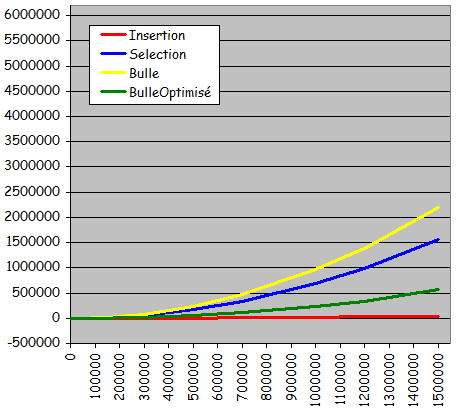
Temps de tri pour des sťries quasi-triťes
(ŗ partir de l'ťtat triť, 10% de permutations entre valeurs voisines)
- Performances encore en progression sauf pour le tri par sťlection (inchangť)
- Tri ŗ bulle optimisť trŤs intťressant (c'est nouveau) par rapport au tri ŗ bulle sans optimisation
- Tri par insertion : Le plus rapide
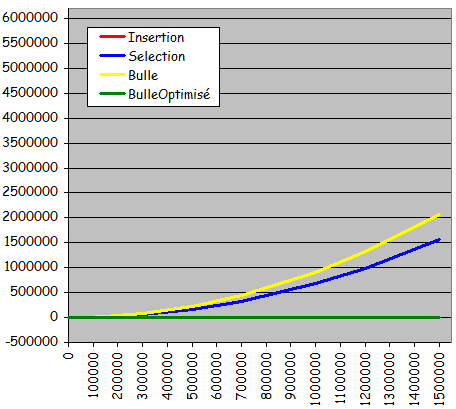
Temps de tri pour des sťries triťes
- Tri par insertion et tri ŗ bulle optimisť extrÍmement rapides (dťtection trŤs efficace du tri prťexistant)
- Accťlťration du tri ŗ bulle mais de maniŤre peu intťressante par rapport aux deux algorithmes prťcťdents
- Tri par sťlection inchangť
- Comparaison des tris par fusion et rapide
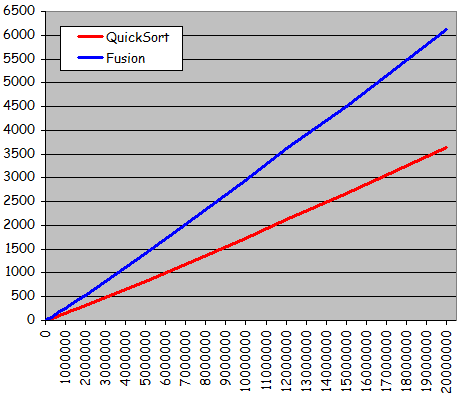
Temps de tri pour des sťries totalement alťatoires
- Tri rapide plus rapide que tri par fusion : Gain uniforme d'environ 40%
- Courbes ressemblant ŗ des droites
- Sťries quasi-triťes (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
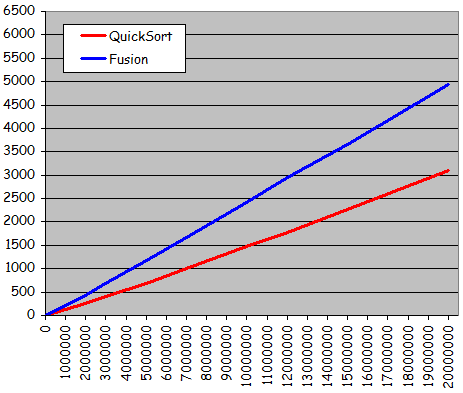
Temps de tri pour des sťries quasi-triťes
(ŗ partir de l'ťtat triť, 10% de permutations entre valeurs d'indices quelconques)
- Tri rapide toujours plus performant pour un gain d'environ 40%
- Sťries quasi-triťes (ŗ partir de l'ťtat triť, 10% de permutations entre valeurs voisines)
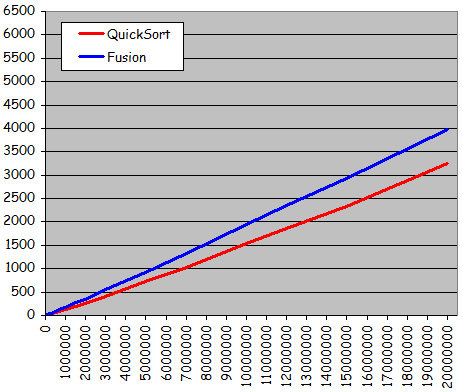
Temps de tri pour des sťries quasi-triťes
(ŗ partir de l'ťtat triť, 10% de permutations entre valeurs voisines immťdiates)
- Tri rapide plus efficace que tri par fusion : Gain d'environ 20%
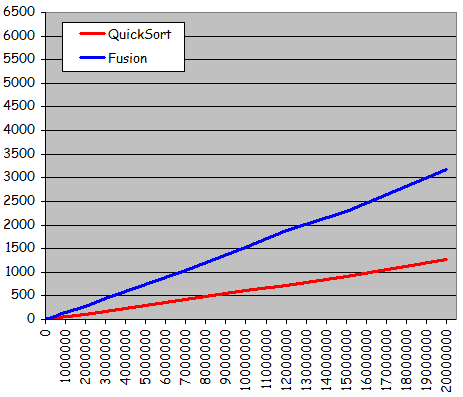
Temps de tri pour des sťries triťes
- Tri rapide encore le plus rapide : Gain uniforme d'environ 60%
- Pour de trŤs grands ensembles de donnťes, tri rapide toujours plus intťressant que le tri par fusion
IntrinsŤquement plus rapide et meilleure exploitation d'une ťventuelle prť-organisation de l'ensemble ŗ trier
- Mťthodes de tri dichotomiques incommensurablement supťrieures aux mťthodes de tri non dichotomiques quand utilisťes sur de grands ensembles
- Rapiditť comparťe des diffťrents algorithmes pour les ensembles de petite taille
- Performances sur des suites alťatoires de petites tailles
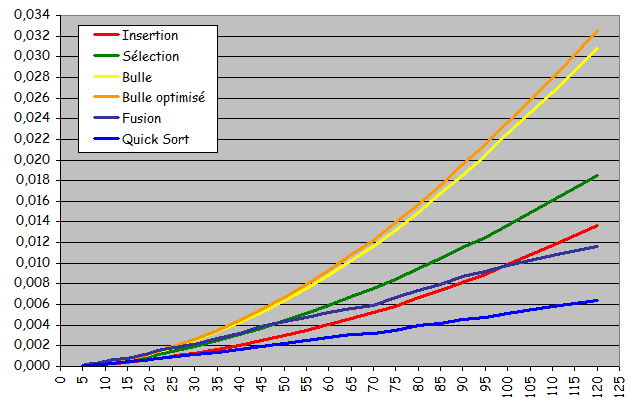
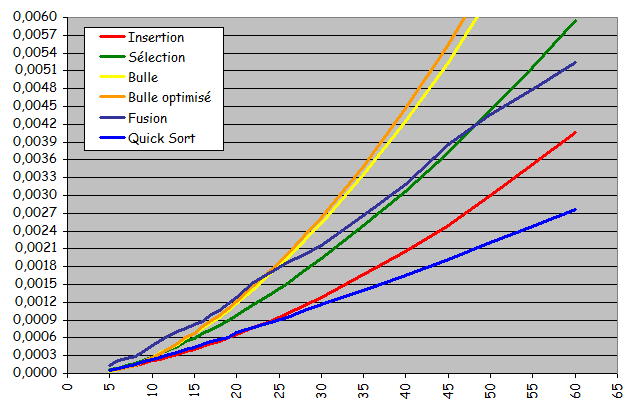
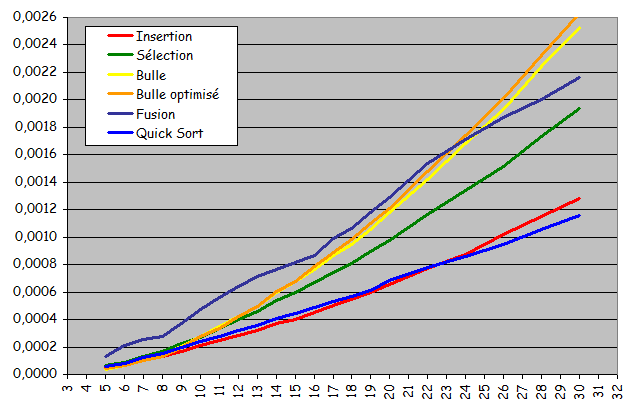
- Tris rapide et par fusion assez rapidement (taille voisine de 100) les plus rapides
(Ils le restent dťfinitivement avec un avantage qui ne fait que croÓtre)
- Jusqu'ŗ une taille voisine de 25, tris par insertion et rapide de performances voisines (lťger avantage pour le tri par insertion)
- Le tri rapide est "toujours" le plus rapide. ProblŤme, c'est celui qui est le plus difficile ŗ implanter.
|